小規模で特化したモデルは、訓練されたタスクにおいて、フロンティアを走る汎用モデルに匹敵する性能を、その一部のコストとレイテンシで実現できます。
私たちは Applied Compute と提携し、この仮説を検証するために RL(強化学習)を用いたバグ検出モデルの訓練で連携しました。その成果がSWE-checkです。これは内部の分布内評価においてフロンティアと同等の性能(Opus 4.6 との F1 スコアの差が 0.09 から 0 へ)を達成し、分布外評価においても有意な進歩(同スコア差が 0.49 から 0.29 へ)を遂げています。
分布外評価における純粋な能力という点では、SWE-check は依然としてフロンティアに後れを取っていますが、その桁違いに高速なウォールクロック時間(実時間)と安価な推論コストにより、フロンティアモデルでは実現不可能だった、即座で無料のバグ検出体験を可能にします。私たちはこのモデルの改善を続けており、データ生成パイプラインへのさらなる取り組みにより、分布外評価におけるフロンティアとの差も縮められると確信しています。SWE-check のプレビュー版は、本日「Windsurf Next」で利用可能となり、間もなく一般の Windsurf でも公開される予定です。
私たちがこれを実現した方法は以下の通りです。
- RL 中に本番環境とネイティブに統合する
- 望ましいグローバル指標をサンプルレベルの報酬に変換する「報酬の線形化」と呼ぶ新技術の採用
- 能力と製品の使用方法パターンの両方に適合したモデルを構築するための、複数段階のポストトレーニング(追加学習)の導入
SWE-check エージェントとその要件
SWE-check エージェントは現在の差分(diff)を分析し、その変更によって引き起こされた可能性のあるバグをフラグ付けします。

新しい設定フラグにより、出力値がタイムスタンプから正規化された分数へ静かに切り替わります。各変更ファイルは内部的には一貫していますが、問題を検出するには、仮定がどこで分岐しているかを確認するために、3 つのファイルにまたがるデータ契約を追跡する必要があります。
これは一般的なコード分析タスクとは異なります。通常のチャットインターフェースで動作するコーディングエージェントとは異なり、SWE-check エージェントは Windsurf で美しくレンダリングされるバグの説明と修正を含む構造化された出力を生成します。
以下は、モデルが訓練されているタスクの種類を理解していただくために、訓練データセットから取得した正解(グラウンドトゥルース)のバグ例です。
リポジトリ: block/goose
コミット: cd0b7d69
このコミットに遡るバグを修正する PR: #5066
バグ 1: 並行処理とスレッディング - 重大度 高(2 箇所の変更)
- 説明: コードは、拡張機能のミューテックスガードを保持したまま、self.extensions.lock().await.keys() によって返されたキービューを反復処理していました。ループ本体では read_resource_from_extension への呼び出しを待機(await)していましたが、これ自体が同じ self.extensions ミューテックスのロックを試みる可能性があります。再ロックの試行につながる待機をまたいでミューテックスガードを保持し続けると、再ロックが要求される前に元のガードが解放されないため、デッドロックが発生します。これは、拡張機能からリソースを読み取ろうとした際に拡張機能マネージャがハングする現象として現れました。
- 修正: 反復処理して拡張機能固有のロジックを待機する前に、コードは現在、ロックを保持したままキーをクローンして拡張機能名を所有された Vec<String> に収集し、直ちにロックを解放するように変更されました。その後の反復は収集された名前で実行され(ミューテックスは保持されない)、各名前の参照を渡して read_resource_from_extension を呼び出します。これにより、待機をまたいで拡張機能ミューテックスを保持することがなくなり、デッドロックの原因となっていた再入可能なロックの試行が排除されます。また、この処理の理由を文書化するために、収集処理の上に簡潔な説明コメントも追加されました。
- グラウンドトゥルースのバグ修正:

訓練中、モデルはソースコミットにチェックアウトされたリポジトリを持つサンドボックス内で起動し、識別したバグの説明と修正を出力する役割を担います。これらのバグは、そのソースコミットのグラウンドトゥルースのバグと比較されます。
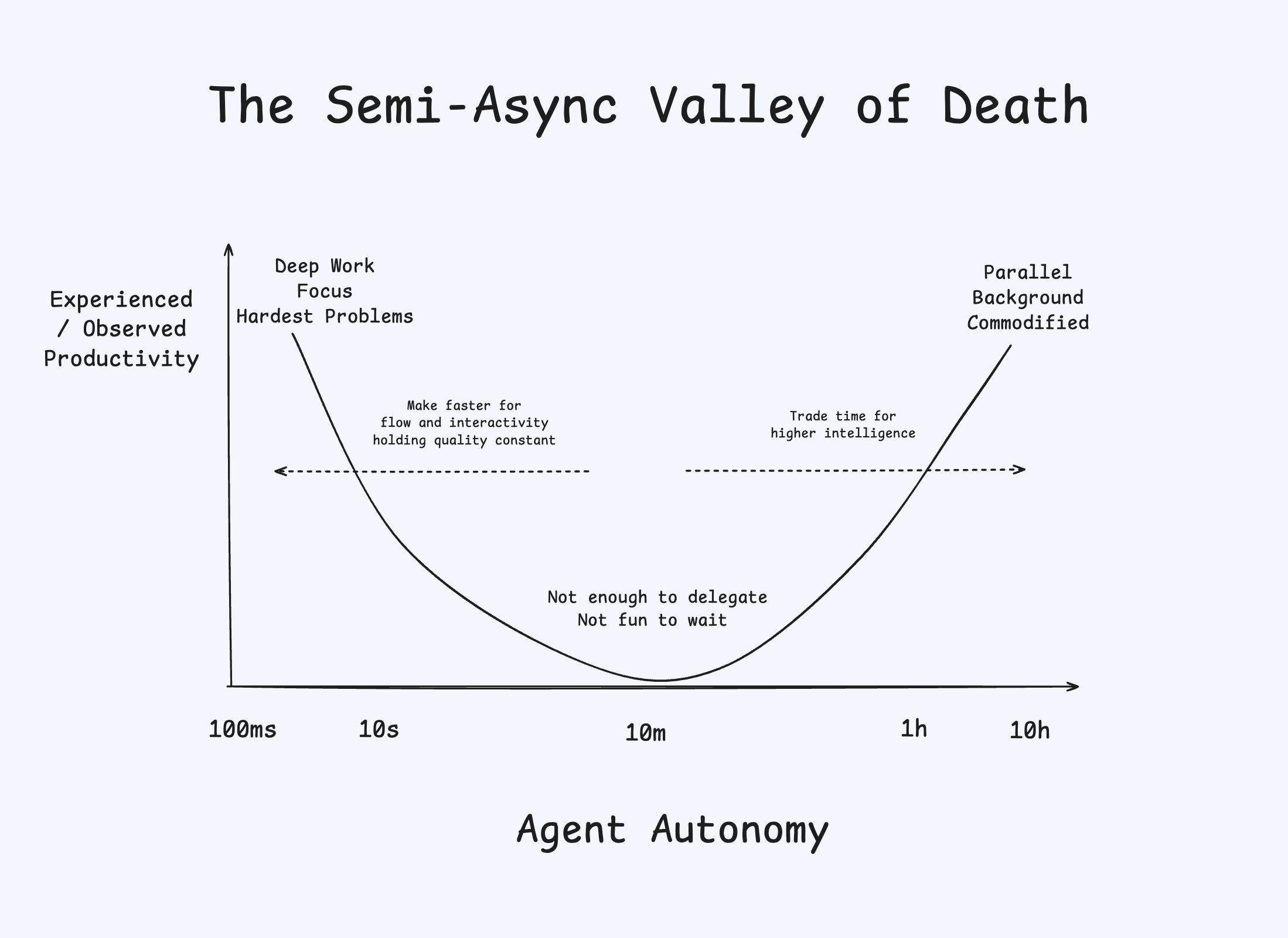
また、エージェントはほぼリアルタイムで動作し、ユーザーをフロー状態に保つ必要があります。私たちが「セミ非同期の死の谷」と呼ぶ状態を何としても回避する必要があるのです。幸い、Cerebras などの推論プロバイダーを利用することで、最終的な出力までの数秒の間に、数千トークンに及ぶ高密度な中間思考を実行することが可能です。
{kind=link}
同時に、モデルは極めて高品質である必要があります。微妙なバグが存在する場合は確実に検出しつつ、取るに足らない偽陽性でユーザーを苛立たせないことです。RL 訓練に進むことを決める前、私たちは同僚たちに SWE-check ハーネス上で、既成のフロンティアモデル(オープンソース、クローズドソースの両方)をドッグフーディング(社内テスト)させました。その結果、品質基準を満たすフロンティアモデルは、IDE 内でのオンデマンドなバグ検出には遅すぎ、高価すぎることが判明しました。これが、このタスクにおいて極めて特化し、高速かつ有能なオープンソースモデルを RL 訓練する動機となりました。
私たちは主に 2 つの評価を行いました。
- 訓練分布を構成する他のタスクから分離して保持された、データパイプラインで生成されたタスクのランダムなサブセットによる分布内評価。
- Cognition のコードベース内で内部的に収集され、訓練プロセス中は完全に保持(非公開)されていたバグのコレクションによる分布外評価。
以下は、最終的に訓練されたモデルが、フロンティアのクローズドおよびオープンソースモデルと比較してどのようにパフォーマンスしたかを示しています。

本番環境の設定を模倣した訓練
小規模で、高速かつ安価な専門モデルは、その「尖った」能力(専門分野)においてフロンティアのパフォーマンスに到達させることができます。私たちの選択した専門分野である SWE-check タスクにおいて、これら 3 つの軸すべてで最高の結果を提供するためには、モデルが本番環境で提供されるのと同じ環境を再現する必要がありました。これにより、訓練中に見られた向上が、Windsurf IDE におけるエンドユーザー体験の向上に直接反映されることが保証されます。
そのために、訓練用サンドボックス内に Windsurf ハーネスで利用可能なツールセットを複製しました。また、多様なプログラミング言語にわたる多様なバグタイプを含むデータセットをキュレーションし、その分布が生産環境で期待されるものを代表するよう、共に反復して調整を行いました。
また、SWE-check エージェントの初期バージョンのドッグフーディング試験中に得られたユーザーの行動と、訓練報酬を整合させることにも注力しました。例えば、ユーザーが SWE-check を呼び出してからオフに切り替えるまでの時間に関する統計データなどを分析しました(詳細は次節で述べます)。
そして最も重要だと考えているのは、複数のモデルを反復して訓練し、ドッグフーディングと密接なフィードバックループを構築したことです。報酬関数に対するモデルの訓練に多大な労力を費やしましたが、最終的に最も重要なのは人々の感覚と、実際の作業においてエージェントがどのように感じられるかということです。エージェントをドッグフーディングした人々から、各イテレーションごとに極めて価値あるフィードバックをいただきました。
例えば、あるイテレーションで、「コードブロック内の変数の定義を 1 つ確認するだけで正しいと分かるような場面で、モデルが常にバグを報告してくる」というフィードバックを受け取りました。私たちは、エージェントが定義を調べたり参照を見つけたりするのに役立つ、ターン効率の良いトレースツールにアクセスできていないことに気づきました。そこで、これらの新しいツールを Windsurf および訓練環境に構築・公開し、再訓練を行いました。
専門化プロセスから得られた重要な教訓は、本番環境からのフィードバックが直接的に訓練の実行を推進するということです。モデルの訓練実行に含まれるすべての要素は、本番環境の側面や実際のユーザーからのフィードバックに直接その源流をたどることができます。
報酬関数の設計方法
ポストトレーニングで使用される報酬は、モデルの振る舞いを決定します。私たちの技術報告書では、以下の 2 つの主要なアイデアに焦点を当てています。
- 報酬の線形化: 集団レベルの統計量をハルクライミング(山登り法)するための代理となる、サンプルレベルの報酬を提供します。ユーザーの選好を代表するグローバル指標を取得し、各個別のサンプルに割り当て可能な報酬に変換します。
- 二段階のポストトレーニング: 最初に能力を最大化し、次にレイテンシを削減することでモデルを製品の使用パターンに適合させます。能力と使用パターンの両方を捉える単一の報酬関数に対して訓練するよりも、ポストトレーニングをこれらのフェーズに分割する方が、より強力なモデルが得られることが分かりました。
報酬の線形化
訓練の設定を形式化することから始めます。各ロールアウトτには、それ固有のグラウンドトゥルースのバグセット(0 の場合もあります)があります。予測されたバグのセットは、以下のようにスコア付けします。
- まず、単純な LLM ジャッジパスを使用してバグが適切にスコープされているか確認します。リスト内のバグが実際には 2 つの異なる問題の集合体である場合、スコアを 0 にします。
- 次に、リスト内の予測された各バグが、グラウンドトゥルースのバグのいずれかと一致するか確認します。
- これらのチェックの結果から、サンプルレベルの適合率(Precision)と再現率(Recall)を計算します。これらをそれぞれP(τ)およびR(τ)と定義します。これらは常に 0 から 1 の間の数値であるべきです。エッジケースは以下の通り処理します。
- 予測されたバグもグラウンドトゥルースのバグもない場合、適合率と再現率を 1 に設定します。
- それ以外で、予測されたバグのリストとグラウンドトゥルースのバグのリストのどちらか片方のみが空の場合、適合率と再現率を 0 に設定します。
これらのスコアを多数のサンプルにわたってどのように集約するでしょうか。これには 2 つの妥当な方法があります。
- 真陽性(TP)、偽陽性(FP)、偽陰性(FN)のグローバルな合計数を集約してグローバルな適合率と再現率を計算し、それらを組み合わせてf_βスコアを算出する。
- サンプルにわたってP(τ)とR(τ)を平均して平均適合率と平均再現率を求め、それらを組み合わせてf_βスコアを算出する。
グラウンドトゥルースのバグが多数ある例で過度に良いパフォーマンスを発揮し(その代償として、バグが少ない/ない例でのパフォーマンスは低くなる)、モデルに偏りを持たせたくないため、私たちは 2 つ目の選択肢を選びました。
🚨βの選択:モデルの初期イテレーションではβ=1を使用し、ドッグフーディング中に多くの無害な差分をバグとして検出する偽陽性が多数発生しました。これを軽減するため、適合率を重視するβ=0.5への変更を決定しました。
R_pop = E_τ[R(τ)]およびP_pop = E_τ[P(τ)]と定義します。最終的に、モデルには以下の指標を増加させることを目指してもらいます。

このグローバル指標を踏まえると、サンプルレベルの報酬はどうあるべきでしょうか。重要な観察結果として、以下を直接使用することはできません。

なぜなら、f_β(τ)を平均してもf_βにはならないからです。これが、私たちが「報酬の線形化」というアイデアを着想した動機です。これはP_popとR_popに関するf_βの 1 次近似を計算するもので、これにより平均化が実際に機能するようになります。
私たちはP_pop、R_popの初期値(これらをP_pop,initおよびR_pop,initと呼びます)、および TP/FP/FN レートの初期分布について十分な見通しを持っているため、P_popとR_popに関する適切な 1 次線形近似を用いてf_βの値を近似できます。

🚨 1 次近似が TP/FP/FN レートの初期値を認識した上で行われることが重要です。私たちの実行では、TP/FP/FN レートの変化が実行期間中に結果の傾きを劇的に変化させることはなかったため、固定された線形化を使用しました。初期値が大きく乖離する場合は、訓練中に 1 次近似を再較正することで、この方法を一般化できる可能性があります。
したがって、有効なサンプルレベルの報酬関数(上記の望ましいf_β近似に平均されるため)は以下のようになります。

実際には、報酬関数をシフト・スケールできるため、y=1 を強制し、すべての定数項を削除することができます。私たちの場合、最終的にサンプルレベルの報酬reward(τ) = ½・P(τ) + R(τ)を使用することになりました。各サンプルに対してこの報酬reward(τ)を受け取るモデルは、望み通りにグローバルなf_β指標を向上させていくことになります。
二段階のポストトレーニング
私たちの目標は、フロンティアのパフォーマンスを持ちながら、はるかに優れたレイテンシプロファイルを持つモデルを訓練することでした。最も効果的な訓練アプローチは、そのプロセスを 2 つの異なるフェーズに分割することであることが分かりました。これら 2 つのフェーズは報酬関数のみが異なり、訓練設定の残りは全く同じです。
- 能力の最大化: 報酬関数は、報酬の線形化のセクションで計算した基本の報酬関数です。この報酬をハイクすることにより、モデルはバグ検出スキルそのものの最大化に注力し、レイテンシの増加に対してペナルティを受けません。能力の最大化が、訓練プロセス全体の大部分を占めました。
- 製品との整合: 報酬関数は、基本の報酬関数に追加の「レイテンシペナルティ」を加えたものです。レイテンシペナルティを計算するため、まず完了トークン数とツール呼び出しのターン数を使用してロールアウトのレイテンシを推定しました。次に、SWE-check エージェントの初期の内部バージョンのドッグフーディングデータから、ユーザーが SWE-check を呼び出してからオフに切り替えるまでの時間の統計分布を観察しました。

この分布は、ユーザーをフロー状態に保つために許容される時間の代理指標として機能しました。次に、この分布の累積分布関数(CDF)を計算し、推定されたレイテンシに比例して増加するペナルティを定義するために使用しました。ある時間 t における CDF は、その時点で離脱してしまっているユーザーの割合を示します。
ペナルティは、即座の応答で 0 となり、末尾で 1 となるように正規化し、バケットの中央値の間で線形補間しました。

製品との整合を目的とした報酬により、モデルは冗長なトークンを削減し、並列ツール呼び出しを改善するよう促されました。これは、ユーザー体験に必要以上のパフォーマンス低下を犠牲にすることなく行われました。製品との整合のフェーズは、訓練の計算量という点で、能力の最大化のフェーズよりもはるかに短いものでした。
この二段階アプローチは、最初から単一の統合された報酬関数で訓練する代替案よりも優れた性能を発揮しました。能力と製品の制約を同時に最適化しようとすると、モデルは局所最適解に収束しがちでした。例えば、レイテンシ目標は満たしつつも本物のバグを見逃してしまうような、極めて高速だが分析が浅い行動を学習してしまうなどです。フェーズを分離したことで、モデルはまずタスクに対する真の理解を発達させ、その後でその理解を効率的に圧縮することを学べるようになりました。

さらに、ポストトレーニングの第 2 フェーズでは以下のことが観察されました。
- 最初は、レイテンシペナルティが減少しても、モデルのパフォーマンス低下は最小限でした。
- その後、レイテンシペナルティが減少し続けるにつれ、モデルのパフォーマンス低下がより顕著になり始めました。
したがって、第 2 フェーズは調整可能なノブであり、私たちのユースケースに最も適合する正確なパフォーマンスとレイテンシのプロファイルを選択するために使用できます。私たちの場合、前述した製品の使用パターンに基づいて、このパレートフロンティア上の点を選択しました。
結論
要約すると、モデルの専門化は、製品の機能と深く整合した、より良いレイテンシ、コスト、ユーザー体験プロファイルでフロンティアのパフォーマンスに近づくための強力なツールです。
ハーネスとのネイティブな統合により、訓練での向上が生産環境に反映されることが保証されました。頻繁なドッグフーディング試験により、ユーザーのフィードバックを迅速に訓練レシピの変更へと変換することができました。報酬の線形化を使用することで、製品のパフォーマンス指標を訓練用のサンプルレベルに効果的に要約することができました。ポストトレーニングを複数のフェーズに分割したことで、中核タスクにおける能力と製品のレイテンシ要件という 2 つの異なる目標を、モデル訓練においてバランスよく達成することが可能になりました。
最終的なモデルにはまだ改善の余地があります。パレートフロンティア上にはありますが、このタスクにおいて圧倒的に最も有能なモデルというわけではありません。議論した訓練レシピは、分布内および分布外の評価の両方で効果的にハイクライミング(性能向上)することが証明されており、より広範なデータミックスと改良されたベースモデルにより、時間の経過とともにパフォーマンスの向上が続くと予想しています。
SWE-check のプレビュー版は、cmd+U ショートカットを使用してWindsurf Nextで今日からお試しください。まもなく一般の Windsurf でも利用可能になります。